機械学習でナノ合金、半導体、レアアースの新材料を予測 インド
インド科学技術省は5月31日、機械学習(Machine Learning: ML)を活用しナノスケールでの合金のデザインマップを開発し、バイメタルナノ合金を形成する金属ペアのマッチング予測を可能にしたと発表した。この研究はインド政府が2015年から推進している国家スーパーコンピューティング・ミッション(National Supercomputing Mission)の成果の一環。
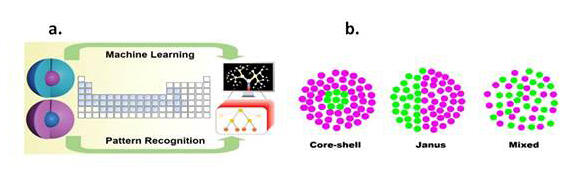
このナノ合金は、コアシェル・ナノクラスター合金と呼ばれ、一方の金属がコアを形成し、もう一方がシェルとして表面にとどまるもので、様々な分野での応用が期待される。
機械学習モデルなど(PIB発表による)
原子のコアやシェルの選択においては、凝集エネルギー差、原子半径差、表面エネルギー差、2つの原子の電気陰性度など、さまざまな要因が関係している可能性があるが、ナノクラスター合金においては、どのような条件でコアシェル構造が形成され、どの金属がコアを形成し、どの金属がシェルとして表面にとどまるのかはとても重要である。
周期表には、アルカリからアルカリ土類までの異なるカテゴリーの金属が95種類あり、それらは4,465組のペアを形成する可能性がある。これらの金属がナノクラスター合金を形成する際にどのような挙動を示すかは、実験的に解明することは不可能であるが、MLによって、これらのペアの挙動などを予測することは可能である。MLでは、明確に定義された属性を持ついくつかのパターンを入力することで、パターン認識するように学習させることで、入力されるデータが増えれば未知のデータに対するコンピュータの認識精度は高くなる。
科学技術省の傘下のS.N.ボーズ基礎科学センター(S.N.Bose Centre for Basic Sciences)では、アルカリ金属、アルカリ土類金属、塩基性金属、遷移金属、p-ブロック金属のさまざまな二元組み合わせについて表面―コア相対エネルギーを計算し、903通りの組み合わせからなる大規模データセットを作成した。
Journal of Physical Chemistry 誌に掲載された論文(*)では、この大規模データセットに対してMLという統計手法を適用し、コアシェル構造を駆動する主要な属性を調査している。原子番号の小さい軽い金属がコアに含まれるコアシェル構造をタイプ1、重い金属がコアに含まれる構造をタイプ2に分類した。データセット内の各データポイントを特徴付けるために、多くの属性が構築された。MLモデルの性能は既存の実験データと比較され、MLモデルが信頼できることが証明された。
次にコアーシェルパターンを駆動する支配的な属性を分析した。その結果、アルカリ金属-アルカリ土類、遷移金属-遷移金属などのサブセットの組み合わせによって、主要因子の相対的重要度が異なることがわかった。また、2種類の原子の凝集エネルギーの差が非常に小さい場合、ナノクラスターは両方の金属のランダムミックスを構成し、凝集エネルギーの差が非常に大きい場合、原子はA原子の面とB原子の面を持つ2面構造に分離することが明らかにされ、それは、2つの顔を持つギリシャ神話の神にちなんでヤヌス構造と呼ばれる。
このように、MLとナノサイエンスを結びつけて、ナノクラスターにおける金属原子の混合パターンを追跡し、ナノクラスター合金用の金属ペアを選択するためのデザインマップの基礎を形成することに成功した。さらに、2つの異種半導体の接合部に形成される不均質構造で、LED、太陽電池、太陽光発電などのデバイスの2つの半導体のヘテロ接合に用いられるヘテロ構造の種類を、かなり正確に予測できることも確認された。
サイエンスポータルアジアパシフィック編集部


